Learn how large-scale cloud platforms evolve using Kubernetes,
microservices, service mesh concepts, observability, CI/CD, and DevOps
best practices.

Introduction
Modern internet platforms handle billions of API requests every day. Every ride request, food delivery, payment transaction, map update, customer notification, and driver location depends on distributed software systems running around the clock. For global technology companies, even a few minutes of downtime can impact millions of users and result in significant financial losses.
As businesses expand, traditional monolithic applications become increasingly difficult to maintain. A single codebase handling every feature creates deployment bottlenecks, slows development, and increases the risk of production failures. Scaling individual components independently becomes almost impossible, making innovation slower and operations more complex.
To overcome these challenges, organizations embrace cloud-native technologies such as Docker, Kubernetes, microservices, and DevOps automation. Kubernetes has emerged as the industry standard for container orchestration because it provides automated deployment, self-healing, service discovery, horizontal scaling, and efficient resource management.
This article explores the engineering principles behind operating applications at enterprise scale. Rather than focusing on a single implementation, it explains the modern Kubernetes ecosystem, the role of service mesh and observability, and the DevOps practices that help engineering teams build reliable, scalable, and production-ready cloud platforms.
Why Kubernetes?
Kubernetes has become the preferred orchestration platform for enterprises because it automates many operational tasks that were once performed manually.
Organizations adopt Kubernetes to achieve several important goals:
-
Automate application deployments
-
Improve system availability
-
Scale workloads automatically
-
Optimize infrastructure utilization
-
Standardize software delivery
-
Support cloud-native microservices
-
Simplify container orchestration
-
Improve disaster recovery
Instead of manually managing servers and applications, engineers describe the desired infrastructure using declarative configuration files. Kubernetes continuously works to maintain that desired state, automatically recovering from failures whenever possible.
From Monolith to Microservices
Many organizations begin their software journey with a monolithic architecture, where all business functionality is packaged into a single application. While this approach works well during the early stages of development, it becomes increasingly difficult to scale as the business grows.
A single deployment means that even a small code change requires rebuilding and redeploying the entire application. Different teams working on unrelated features can unintentionally affect one another, making releases slower and increasing operational risk.
Modern engineering teams solve this challenge by adopting a microservices architecture.
Instead of one large application, functionality is divided into smaller, independently deployable services.
Typical microservices include:
-
Authentication Service
-
User Profile Service
-
Payment Service
-
Pricing Service
-
Notification Service
-
Maps Service
-
Search Service
-
Analytics Service
Each service has its own lifecycle, allowing development teams to build, test, deploy, and scale independently. This approach improves agility, fault isolation, and overall system resilience while enabling teams to choose the most appropriate technology stack for each service.
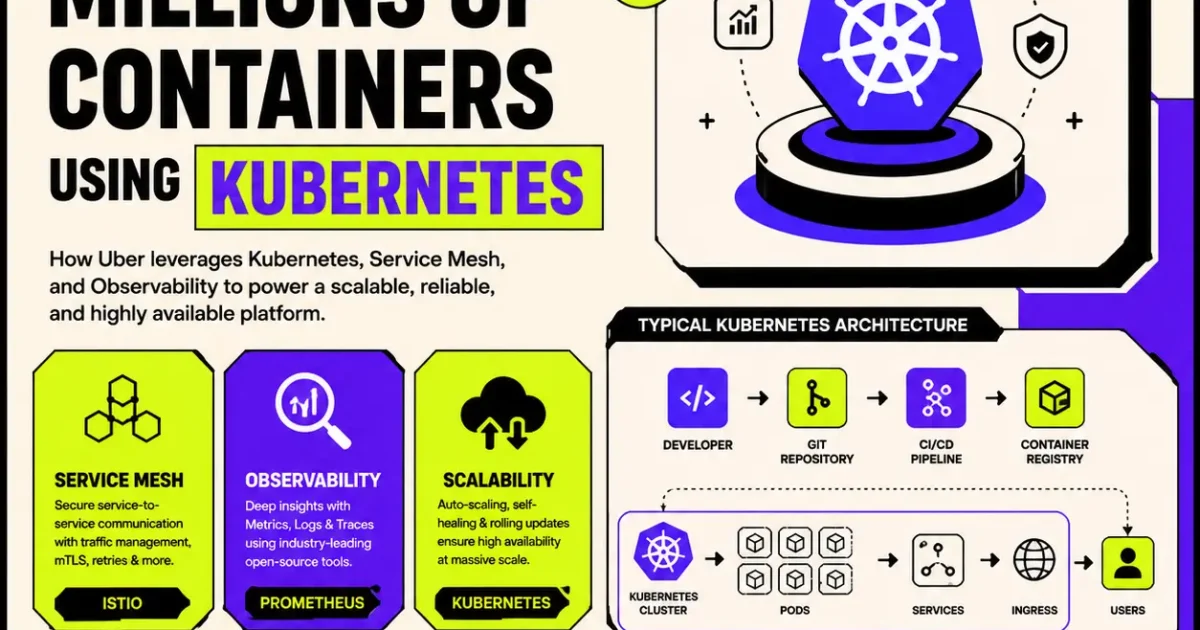
Typical Kubernetes Architecture
A modern Kubernetes-based deployment pipeline follows a standardized workflow that automates software delivery from development to production.
Development Workflow
Developer -> Git Repository -> CI Pipeline -> Container Image Build -> Container Registry -> Kubernetes Cluster -> Pods -> Services -> Ingress Controller -> End Users
This automated workflow enables engineering teams to release software quickly while maintaining consistency, reliability, and security.
Core Kubernetes Components
Every Kubernetes cluster consists of several essential components:
-
API Server – The central management interface for the cluster.
-
Scheduler – Assigns workloads to available worker nodes.
-
Controller Manager – Ensures the cluster continuously matches the desired state.
-
etcd – A distributed key-value database storing cluster configuration.
-
Worker Nodes – Virtual or physical machines that execute application workloads.
-
kubelet – An agent responsible for communicating with the Kubernetes control plane.
-
Container Runtime – Software such as containerd that runs application containers.
Together, these components create a highly resilient platform capable of automatically recovering from failures and managing thousands of running containers.
Service Mesh Concepts
As organizations adopt hundreds or thousands of microservices, managing communication between services becomes increasingly complex.
A service mesh introduces a dedicated infrastructure layer responsible for handling service-to-service communication without requiring developers to implement networking logic inside their applications.
A service mesh provides capabilities such as:
-
Mutual TLS (mTLS) encryption
-
Secure service identity
-
Intelligent traffic routing
-
Automatic retries
-
Circuit breaking
-
Load balancing
-
Policy enforcement
-
Service-level observability
Popular open-source service mesh solutions include Istio and Linkerd, both of which help organizations improve reliability, security, and operational visibility in large Kubernetes environments.
Observability
Modern distributed systems generate enormous amounts of operational data. Simply collecting logs is no longer sufficient to understand application health.
Observability provides engineering teams with complete visibility into production environments through three foundational pillars.
1. Metrics
Metrics provide quantitative measurements about application performance and infrastructure health.
Common examples include:
-
CPU utilization
-
Memory usage
-
Request latency
-
Throughput
-
Error rates
-
Disk utilization
-
Network traffic
These measurements allow engineers to detect anomalies before they impact users.
2. Logs
Logs capture detailed records of application events, infrastructure activities, and system behavior.
Centralized log management enables teams to investigate incidents quickly and understand exactly what occurred during a failure.
Examples include:
-
Application logs
-
Kubernetes events
-
Container logs
-
Security logs
-
Audit logs
3. Distributed Tracing
Distributed tracing follows a single user request as it travels through multiple microservices.
Tracing helps engineers identify:
-
Performance bottlenecks
-
Slow database queries
-
Failed service calls
-
High network latency
-
Dependency issues
Without distributed tracing, troubleshooting complex cloud-native applications becomes significantly more difficult.
Common Observability Stack
Many organizations build observability platforms using open-source tools such as:
-
Prometheus
-
Grafana
-
OpenTelemetry
-
Jaeger
-
Loki
-
Alertmanager
Together, these tools provide comprehensive monitoring, visualization, logging, alerting, and tracing capabilities.
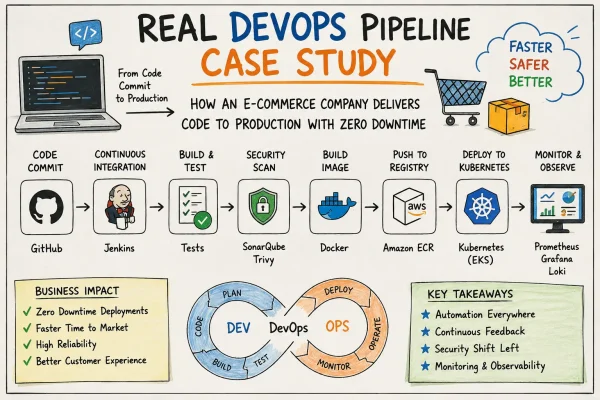
CI/CD Workflow
Continuous Integration and Continuous Deployment (CI/CD) automate the software delivery lifecycle, allowing engineering teams to release features rapidly while maintaining quality and reliability.
A typical Kubernetes deployment pipeline follows this sequence:
Developer -> Create Pull Request -> Code Review -> Static Code Analysis -> Unit Testing -> Build Container Image -> Security Scan -> Push Image to Container Registry -> Deploy to Kubernetes -> Smoke Testing -> Canary Release -> Production Deployment
This automated workflow minimizes manual effort, reduces deployment errors, and supports frequent, reliable software releases.
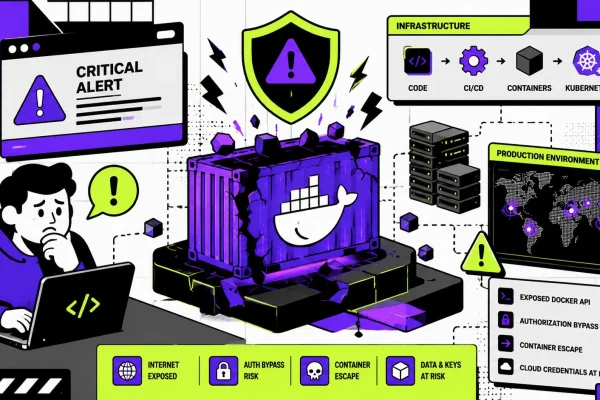
Security Best Practices
Security should be integrated throughout the software delivery lifecycle rather than treated as a final step.
Production Kubernetes environments commonly implement the following practices:
-
Role-Based Access Control (RBAC)
-
Network Policies
-
Secret Management
-
Container Image Scanning
-
Admission Controllers
-
Least Privilege Access
-
Signed Container Images
-
Continuous Vulnerability Assessment
Embedding security into DevOps workflows enables organizations to adopt DevSecOps practices while reducing operational risk.
Autoscaling
One of Kubernetes’ most powerful capabilities is automatic scaling based on workload demand.
Three primary autoscaling mechanisms include:
Horizontal Pod Autoscaler (HPA)
Automatically increases or decreases the number of running Pods based on metrics such as CPU utilization or custom application metrics.
Vertical Pod Autoscaler (VPA)
Adjusts CPU and memory allocations for individual Pods based on observed resource usage.
Cluster Autoscaler
Adds or removes worker nodes according to overall cluster resource requirements, helping organizations optimize infrastructure costs.
Together, these mechanisms ensure applications remain responsive during traffic spikes while avoiding unnecessary infrastructure expenses.
DevOps Lessons
Successful cloud-native engineering extends beyond Kubernetes itself. Organizations achieve long-term success by adopting disciplined DevOps practices.
Key lessons include:
-
Automate repetitive operational tasks.
-
Manage infrastructure using Infrastructure as Code (IaC).
-
Build reliable CI/CD pipelines.
-
Continuously monitor production systems.
-
Design applications for failure and resilience.
-
Use immutable deployments whenever possible.
-
Adopt progressive delivery strategies such as Canary and Blue-Green deployments.
-
Maintain clear operational documentation and incident response runbooks.
These practices improve deployment reliability, accelerate development, and strengthen operational excellence.
Key Takeaways
Kubernetes is far more than a container orchestration platform. It serves as the foundation for modern cloud-native infrastructure by automating deployments, scaling applications, improving resilience, and simplifying operations.
However, Kubernetes alone is not enough.
Successful enterprise platforms combine Kubernetes with observability, automation, security, service mesh technologies, CI/CD pipelines, Infrastructure as Code, and disciplined DevOps practices. Together, these capabilities enable organizations to deliver software faster, recover from failures more efficiently, and build reliable systems capable of serving millions of users.
Frequently Asked Questions (FAQs)
Why do enterprises adopt Kubernetes?
Kubernetes automates deployment, scaling, service discovery, load balancing, and application recovery, making it easier to operate cloud-native applications at scale.
What is a service mesh?
A service mesh is an infrastructure layer that manages secure and reliable communication between microservices while providing traffic management, encryption, observability, and policy enforcement.
Why is observability important?
Observability enables engineering teams to monitor application health, troubleshoot incidents quickly, identify performance bottlenecks, and improve overall system reliability.
How does CI/CD improve DevOps?
CI/CD automates software delivery, reduces manual intervention, improves code quality, accelerates release cycles, and enables frequent, reliable deployments.
What is the role of autoscaling in Kubernetes?
Autoscaling automatically adjusts application resources according to demand, ensuring high performance while optimizing infrastructure costs.
Conclusion
Modern software platforms demand scalability, resilience, automation, and continuous delivery. Kubernetes provides the orchestration foundation that enables organizations to operate distributed applications efficiently, while service mesh technologies improve secure communication, observability delivers deep operational insights, and CI/CD pipelines accelerate software delivery.
When combined with DevOps best practices, these technologies create a production-ready cloud-native ecosystem capable of supporting rapidly growing businesses and mission-critical applications. Organizations that invest in automation, monitoring, security, and continuous improvement are better positioned to deliver reliable digital experiences, reduce operational complexity, and innovate at scale.