Explore how a fictional SaaS company, CloudPulse, responded to the critical Docker Engine vulnerability (CVE-2026-34040) using AIOps, automated remediation, Platform Engineering, and zero-trust container security to patch thousands of production workloads within 24 hours.
Introduction
The speed at which modern organizations deliver software has never been greater. Continuous Integration, Continuous Deployment (CI/CD), Kubernetes, Infrastructure as Code (IaC), GitOps, and Platform Engineering have transformed software delivery from a monthly event into something that happens hundreds of times every day. While these technologies have dramatically increased developer productivity, they have also introduced a new reality: infrastructure vulnerabilities now spread at the same speed as automation itself.
Unlike traditional application bugs that typically affect a single service, vulnerabilities within the container runtime threaten the very foundation of cloud-native infrastructure. Every container running inside a Kubernetes cluster depends on the security guarantees provided by the underlying runtime. If that layer is compromised, even perfectly written applications can become vulnerable.
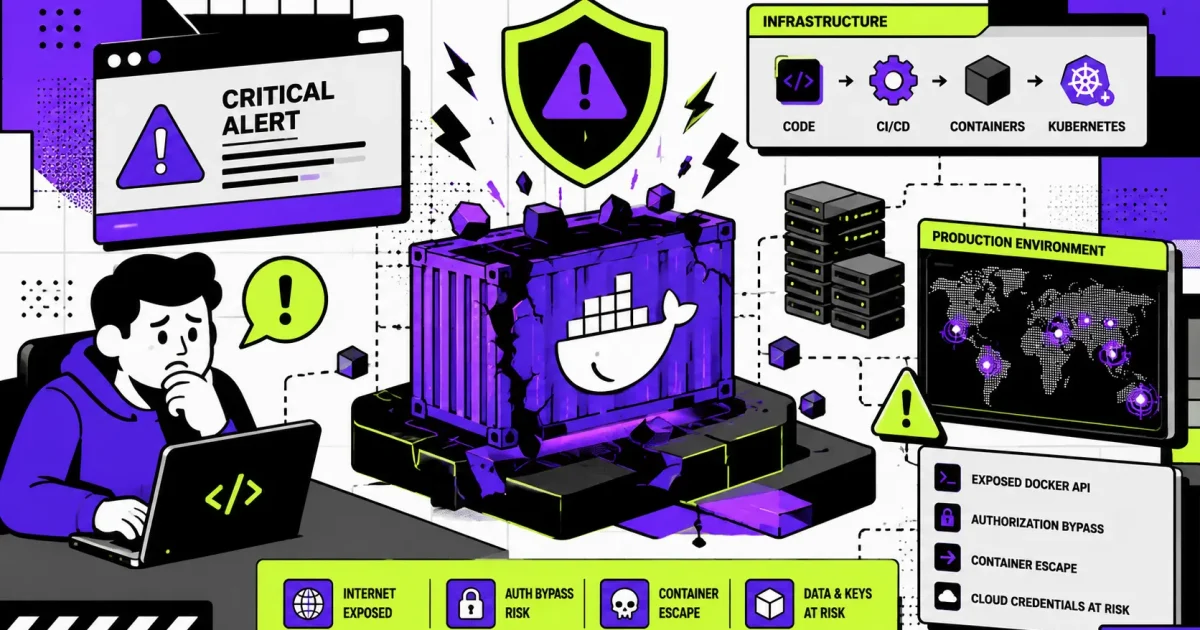
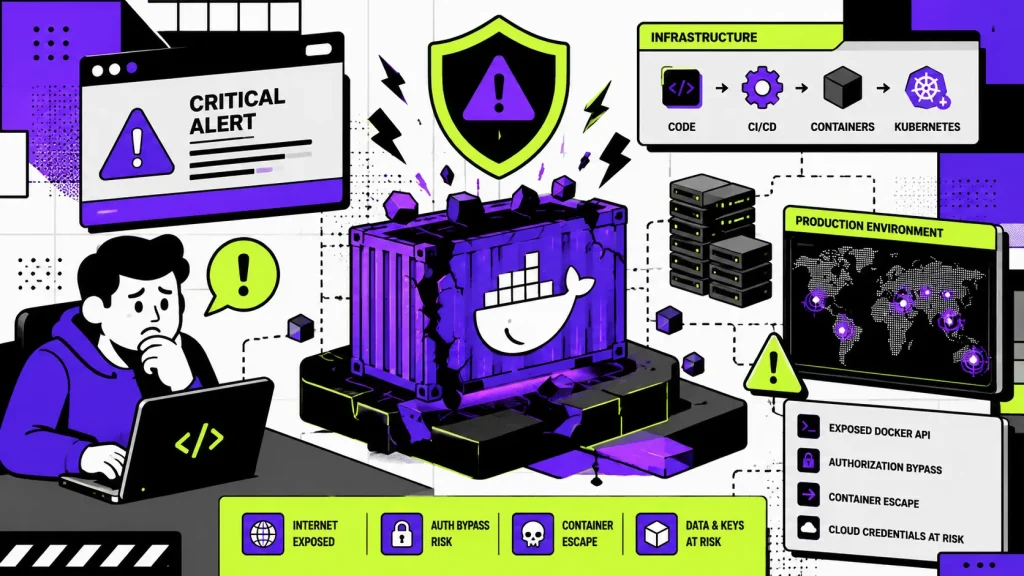
This case study follows the fictional SaaS company CloudPulse, a rapidly growing cloud platform that faced one of the most critical infrastructure incidents in its history. When a severe Docker Engine vulnerability—CVE-2026-34040—was publicly disclosed, the company had less than 24 hours to protect thousands of production workloads before proof-of-concept exploits became widely available.
Rather than relying on manual intervention, CloudPulse leveraged AIOps, automated remediation, GitOps workflows, Platform Engineering, and zero-trust security principles to transform a potentially catastrophic security incident into a textbook example of modern DevOps incident response.
This article explores the complete engineering journey—from crisis detection to automated recovery—and highlights the lessons every DevOps engineer, Platform Engineer, and Cloud Architect can apply to strengthen production environments.
About CloudPulse
CloudPulse is a fictional mid-sized Software-as-a-Service (SaaS) company that provides observability and business intelligence solutions for enterprise customers across healthcare, fintech, logistics, and e-commerce industries. With more than 18,000 active customers distributed across multiple regions, the platform processes millions of API requests every day while maintaining strict uptime requirements.
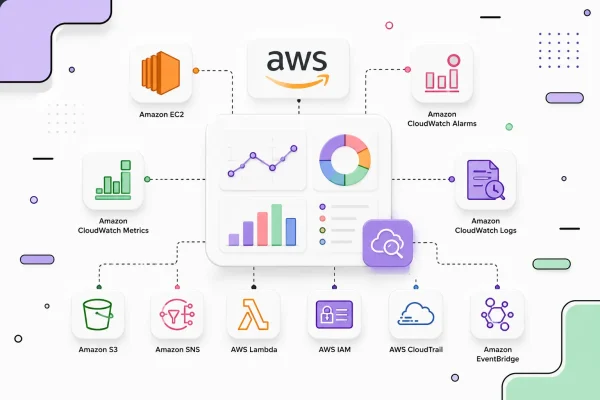
The engineering organization consists of more than seventy developers working across independent product teams. To support continuous delivery without sacrificing reliability, CloudPulse adopted a cloud-native architecture built around Kubernetes, Docker, GitHub Actions, Argo CD, Terraform, Prometheus, Grafana, OpenTelemetry, and HashiCorp Vault.
Every application deployed by the company follows a standardized GitOps workflow. Developers commit code to GitHub repositories, automated pipelines build and scan container images, infrastructure changes are validated using Infrastructure as Code, and Argo CD continuously synchronizes production clusters with version-controlled configuration stored in Git.
This approach enables engineering teams to release new features multiple times each day while maintaining consistency, security, and operational visibility across hundreds of microservices.
Although the platform had been designed for resilience, one unexpected security advisory would soon test every aspect of its engineering maturity.
The Crisis Begins
It was 08:12 UTC on a Monday morning when the first alert appeared inside CloudPulse’s Security Operations Center.
A critical security advisory had just been published describing CVE-2026-34040, a high-severity Docker Engine authorization bypass vulnerability affecting environments that relied on plugin-based authorization mechanisms. Security researchers warned that attackers could potentially bypass authorization controls and execute privileged Docker API operations under specific conditions.
Within minutes, security analysts created an incident ticket, automatically triggering the organization’s Severity-1 response process.
Slack channels dedicated to infrastructure, DevOps, Platform Engineering, Security, and Site Reliability Engineering immediately became active.
- Video conference bridges opened.
- Incident commanders were assigned.
- Engineering managers cancelled routine sprint meetings.
- Every available infrastructure engineer joined the emergency response.
- The atmosphere inside the engineering department changed instantly.
Unlike many software vulnerabilities that only affect specific applications, this vulnerability targeted Docker Engine itself—the foundation upon which every production workload depended.
CloudPulse operated more than 2,300 Docker hosts, forty-two Kubernetes clusters, and over five hundred production microservices.
If attackers successfully exploited a vulnerable Docker daemon, they could potentially create privileged containers, mount host filesystems, extract Kubernetes Secrets, access AWS credentials, and move laterally throughout the infrastructure.
The potential business impact was enormous.
- Customer databases.
- Cloud credentials.
- Payment systems.
- Internal APIs.
Everything depended on securing the underlying container runtime before attackers had an opportunity to weaponize the vulnerability.
The countdown had begun.
Understanding the Risk
One of the first responsibilities of the incident response team was explaining the vulnerability to engineering leadership.
While application developers often think about vulnerabilities in terms of SQL injection, Cross-Site Scripting (XSS), or broken authentication, container runtime vulnerabilities operate at an entirely different layer.
Docker Engine is responsible for creating, managing, and isolating application containers.
It ensures that one application cannot interfere with another and prevents workloads from accessing resources outside their designated boundaries.
The newly disclosed vulnerability threatened those isolation guarantees.
If exploited successfully, attackers could bypass authorization controls protecting the Docker API and perform operations normally restricted to administrators.
Possible attack scenarios included:
- Launching privileged containers.
- Mounting sensitive host directories.
- Reading Kubernetes service account tokens.
- Extracting environment secrets.
- Accessing cloud credentials stored on worker nodes.
- Escaping container isolation.
- Pivoting into internal production networks.
For organizations running hundreds or thousands of workloads, this represented an infrastructure-level emergency rather than a normal application vulnerability.
Every minute without remediation increased organizational risk.
Existing Infrastructure Architecture
Before engineers could begin remediation, they needed a complete understanding of the existing deployment architecture.
CloudPulse followed a modern cloud-native software delivery model.
Every software change passed through an automated pipeline that minimized manual intervention while maintaining strict quality controls.
The deployment workflow looked like this:
Developer --> GitHub Repository --> GitHub Actions --> Docker Image Build -->
Container Image Scanning --> Container Registry --> Argo CD --> Kubernetes Cluster -->
Docker Engine --> Production Microservices --> Customers
This architecture had successfully supported thousands of deployments over the previous two years.
However, the Docker Engine vulnerability existed beneath nearly every layer of this workflow.
Updating application code alone would not eliminate the risk.
The infrastructure itself needed immediate attention.
The Engineering Challeng
At first, the solution appeared obvious.
Patch every Docker Engine installation immediately.
Unfortunately, the scale of CloudPulse’s infrastructure made manual patching nearly impossible.
The company maintained thousands of running containers across dozens of Kubernetes clusters spread over multiple AWS regions.
Each production node required:
- Compatibility validation.
- Infrastructure testing.
- Maintenance planning.
- Controlled rollout.
- Monitoring.
- Rollback capability.
Even if every engineer focused exclusively on infrastructure updates, manually upgrading thousands of nodes would require several days.
Security leadership estimated that complete remediation using traditional operational processes would take between three and five days.
Industry analysts expected proof-of-concept exploits to become publicly available within twenty-four hours.
CloudPulse did not have five days.
It barely had one.
The vulnerability had been identified, but finding the problem was the easy part.
The real test was deploying a verified fix across thousands of containers without introducing downtime, breaking CI/CD pipelines, or impacting customers. Achieving that level of speed and reliability required far more than manual patching—it demanded a completely different way of operating modern cloud infrastructure.
👉 In Part 2, we’ll dive into the complete remediation strategy, including AI-powered vulnerability detection, automated pull requests, GitOps deployments, progressive rollouts, and the engineering decisions that helped CloudPulse secure its production environment within 24 hours. Stay tuned!