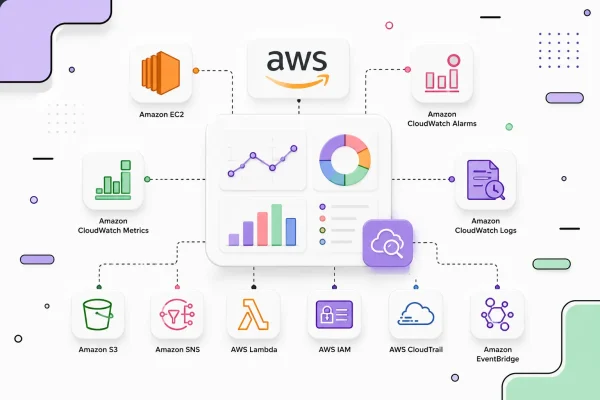
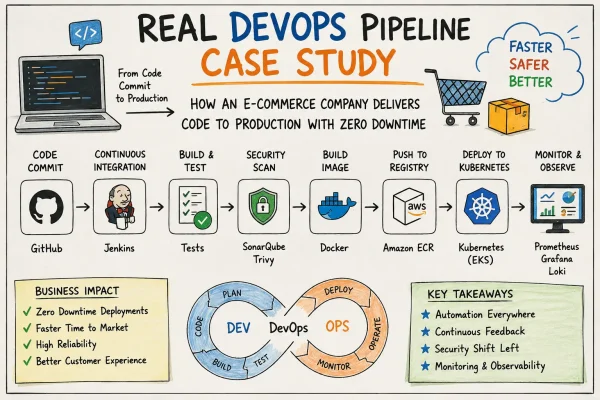
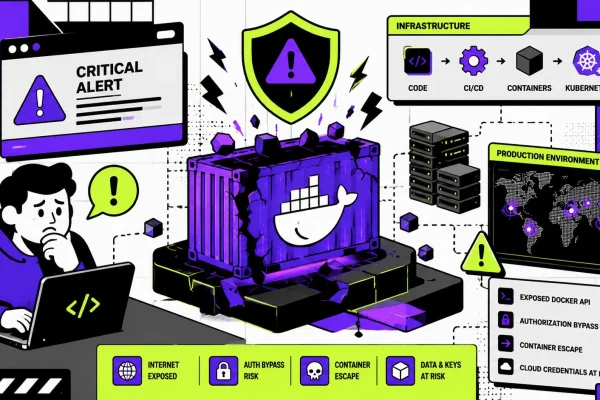
DevOps engineers bridge development and operations, automating deployments and ensuring system reliability under constant pressure. Daily struggles include pipeline failures, tool sprawl, cultural clashes, and security gaps that lead to outages, burnout, and ballooning costs. These challenges persist into 2025 as teams scale cloud-native environments while managing legacy systems.
Pipeline Failures and Instability
CI/CD pipelines break frequently due to flaky tests, dependency mismatches, or environment drift, where dev setups diverge from production. Engineers spend hours debugging intermittent failures, like tests passing locally but failing in staging from unmocked external services. Long build times exacerbate this, as pipelines drag 30+ minutes, halting developer flow, piling up queues during peak hours.
Rollback strategies often falter as well; without robust blue-green deployments, hotfixes introduce new bugs that cascade into outages. In microservices architectures, one service’s failure ripples across the stack, demanding manual intervention under pager duty stress. Practitioners report 40% of incidents stem from these unchecked changes, underscoring the need for gated approvals and canary releases.
Monitoring and Observability Overload
Alert fatigue plagues teams as disparate tools — Prometheus, Middleware, Datadog — flood Slack with noise, burying critical signals in thousands of daily pings. Engineers triage endlessly, correlating logs from Kubernetes pods, AWS Lambda traces, and app metrics without unified views. Poor instrumentation means root-cause analysis takes days, not minutes, especially when traces span services.
Visibility gaps extend to infrastructure; drift detection misses subtle config changes, leading to “works on my machine” syndromes. Without SLO-based alerting, false positives erode trust and lead to custom dashboards that no one maintains. Reddit threads highlight engineers scripting midnight cron jobs just to aggregate metrics, diverting time from innovation.
Cultural Resistance and Team Silos
Legacy operations teams resist automation, viewing IaC as a threat to their gatekeeping role, while developers blame infrastructure delays on “slow IT.” This silo mentality fuels blame games during incidents, with postmortems becoming accusatory rather than constructive. Management demands “faster releases” without cultural buy-in, leading to shadow IT where teams bypass pipelines. Context-switching drains productivity — engineers juggle standups, ticket queues, and fires across time zones. Uneven skill distribution means juniors shadow seniors endlessly, creating bottlenecks in onboarding amid talent shortages. Surveys show that 60% of failures are due to human factors such as miscommunication, not code.
Toolchain Fragmentation and Decision Paralysis
Hundreds of options — Jenkins vs. GitHub Actions, Terraform vs. Pulumi, ArgoCD vs. Flux — create paralysis, with teams stacking incompatible tools. Integrations fail silently, like webhooks dropping in multi-cloud setups, fragmenting workflows across 10+ vendors. License costs are rising as unused tools linger due to a lack of centralized inventory.
Vendor lock-in traps teams; migrating from monolithic Jenkins to Kubernetes-native pipelines reveals hidden dependencies. On-call rotations suffer from tool-specific paging, which pulls engineers out of sleep for niche fixes. Practitioners lament “tool bingo,” where shiny new stacks distract from core automation.
Security and Compliance Gaps
DevSecOps lags as “shift-left” ideals clash with rapid CI/CD—scans block pipelines due to false positives, or, worse, vulnerabilities ship to production. Secret management falters; environment variables leak into Git history despite SOPS or Vault. Compliance audits require manual proofing, halting merges during SOC2 or GDPR audits.
Zero-trust enforcement struggles in dynamic K8s clusters, where RBAC drift allows overprivileged pods. Attack surfaces expand when SBOMs are ignored, exposing supply chain risks such as Log4j variants. Teams report 25% downtime from security scrambles, prioritizing fixes over features.
Skill Shortages and Upskilling Demands
Demand outstrips supply for cloud-native pros versed in GitOps, eBPF tracing, and service meshes. Juniors struggle with production-scale chaos engineering, while seniors burn out from mentoring amid tool churn. Certs like CKA help, but hands-on experience with outages trumps theory — new hires shadow endlessly.
Multi-cloud mastery adds pressure; AWS wizards stumble on GCP IAM quirks. Continuous learning competes with firefighting, with platforms like A Cloud Guru overwhelmed by the 2025 AI/ML wave. Reddit polls rank this as top stressor, with 70% seeking internal academies.
Cost Overruns and Resource Waste
Unmonitored cloud sprawl—zombie EBS volumes, idle EKS nodes—devours budgets, with bills spiking 300% after Black Friday traffic. FinOps tools like Kubecost lag behind autoscalers and miss orphaned resources. Self-service portals enable rogue spins, sans quotas.
Pipeline inefficiency compounds this: parallel jobs on spot instances save pennies but fail unpredictably, driving on-demand costs. Teams scramble quarterly reconciliations, blaming devs for “experiments.”
Scalability and Performance Bottlenecks
As deploys reach 100/day, pipelines choke due to resource contention — shared runners starve under load. K8s scaling hits limits with HPA misfires during bursts, causing 5xx errors. Legacy monoliths resist refactoring into microservices, causing hybrid pains.
Global teams face latency in multi-region deploys; edge caching lags, inflating MTTR. Without predictive autoscaling, spikes overwhelm the system, triggering circuit breakers prematurely.
Documentation and Knowledge Gaps
Runbooks decay as engineers depart, leaving tribal knowledge in chat histories. Onboarding takes weeks, reverse-engineering YAMLs without wikis. Dynamic infrastructure from Helm charts defies static documentation, requiring live demos.
Incident reviews skip action items; quarterly, recycle failures. Tools like Notion help, but adoption wanes sans mandates.
Vendor and Legacy Integration Struggles
Monoliths clash with event-driven architectures; MQ queues bottleneck async flows. Legacy COBOL mainframe block serverless pivots, demanding costly wrappers. Vendor APIs evolve incompatibly, breaking webhooks mid-sprint.
Key Challenges Overview
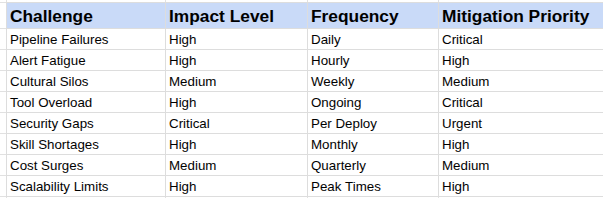
DevOps demands evolve, but addressing these via policy-as-code, IDPs, and DORA metrics yields resilient pipelines. Teams succeeding invest in people-first cultures, cutting MTTR by 50%.